LFS--日志文件系统介绍
Flash的结构简介
由于本文章的主体为对LFS的介绍,介绍Flash也是为了引出LFS,因此这里对Flash的介绍也是点到为止,而不会太过深入.回到正题,开始正式介绍Flash.
Flash是一种新兴的存储介质,一个完整的NAND闪存芯片布局如下图(来自https://flashdba.com/)所示,一个芯片(或者说一个封装)中有多个Plane,而每个Plane中有多个Block,每个Block内又有多个Page,至于Page内就是我们常说的MLC,SLC等颗粒,这些是什么以及怎么通过硬件实现和控制的则不是我们的关注重点.下面描述一下Flash的读写特性.

Flash支持三种最基本的操作:
- 读,基本粒度是Page,也就是说你每次读的基本单位是Page
- 写,基本单位也是Page,不过有一点要注意的是,写之前要对Page进行擦除
- 擦除,擦除的操作就是清空内容,但是擦除的基本单位是Block,也就是说Flash无法做到Page粒度的擦除操作
在描述完上述的基本操作之后,相想必你也意识到了Flash的问题所在:无法精确地更新(包括变更部分内容或者擦除)一个Page,要做到这一点,你需要如下的步骤:
- 找到一个空的Block
- 将目标的整个block赋复制到一个这个空Block中
- 擦除整个目标Block
- 将你要更新的page的内容写入该block中的对应位置
- 将不需要更新的page内容拷贝回原来的地方
- 擦除最开始的空的Block
显而易见,这样做是极不划算的,因为会使Flash的寿命大打折扣,因为每次更新都需要多次擦除不止一个Block.
为了解决这一问题,我们可以使用一种简单的标记法假擦除的方法:
- 找到一个空Block
- 将要更新的Page以及不需要更新的Page写入这个空的block
- 将原来的Block标记为无效
这样做就一次擦除都不需要了,但是也带来了新的问题:首先从传统文件系统的角度来看,最严重的问题是数据块的物理地址(PBA)改了,那我下次读文件不是就读到错误的内容了吗?问题2就是这样做空余的block就会越来越少,但是无效的Block就会越来越多。
面对一个复杂的计算机问题,抽象就是最好的解决办法,现在的Flash都在“逻辑数据块”和“物理数据块”之间添加了一个转换层:每次读写文件都要先经过这个转换层,转换层会根据输入的逻辑地址查找对应的物理地址,然后使用这个物理地址去对应的page中读取。这样一来就解决了问题1,因为我们改变block位置后更新这个转换层的映射表即可。这个所谓的转换层就是闪存转换层(flash translation layer,FTL)。为了解决问题2,这里需要引入一个垃圾回收过程,说简单点就是在后台定期地将无效的Block擦除,并标记为空闲的Block。实际上FTL承担的任务还有擦除均衡等内容,这里就不细说了。
Log-structured File System
简介
上面对FTL的介绍实际上就引出了LFS——日志结构的文件系统。至于为什么这么说,看完后面对LFS的介绍就明白了。
LFS一开始并不是为了Flash设备而设计的,因为它被提出的时候Flash还没那么流行。和传统的文件系统(如Ext4)最不同的事情是,LFS将随机读写转换成了顺序读写。这也是它叫”日志结构”文件系统的原因。LFS将整个存储介质看成一个append only的log文件,每次写入都是顺序写,内容总是追加在日志的最后,下图展示了LFS的基本原理:
1 | |
下面举一个简单的粒子,文件S一开始有ABC三个块(文件系统读写的最小单位):
1 | |
如果在这时候我更新文件S的A,C块,那么这时候块序列就会变成如下这样(暂时忽略元数据的组织):
1 | |
这里加括号的意思就旧的文件块会被标记为无效,而不是直接覆盖,如果覆盖的话就变成随机写了。
在这种结构下LFS有着极高的写入速度,但是显然也存在着很大的问题:随着文件的更新,文件系统内部会产生大量的无效数据块,快速占满整个文件系统。
面对这个问题,相信你也猜到了,就是进行垃圾回收:所谓的垃圾回收,就是在文件系统空闲或者文件系统没有空余空间的时候,对整个文件系统进行重排,删除无效的数据块以腾出空间的过程。
LFS结构简单介绍
在明白原理后,这里对LFS的元数据组织做下简单的介绍,因为后面还要介绍一个现在很流行的LFS实现,因此这里就简单说下。LFS将整个文件系统分为多个段(Segment),每个segment内部有多个Block,Block自身又分为三种:包含文件实际内容的块,存储inode信息的文件元数据块,组织段内Inode信息的inode map块。
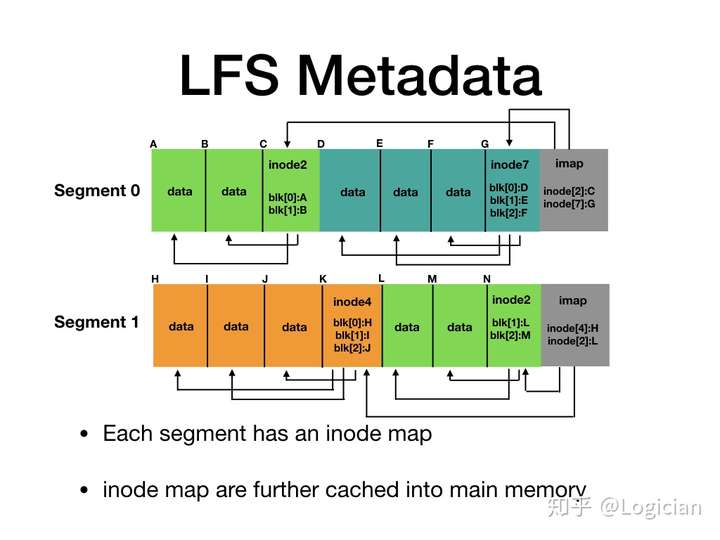
(图来自https://zhuanlan.zhihu.com/p/41358013)
每次向Sgement内写入多个数据块后LFS就会在后面追加一个inode块以对新追加的数据块进行索引,请注意Inode的位置并不固定,因此为了定位Inode的位置,LFS在每个segment尾部追加了一个索引inode的块,称之为Inode map。而每个inode map的位置则缓存在内存中。这样就形成了一个多级索引结构,用于对文件的读写。
在LFS中读取一个inode号为i的文件的流程如下所示:
- 从内存中缓存的inode map中读取所有段中inode为i的地址,也就和i相关的所有inode
- 从每个inode中读取每个相关的data block的位置
- 读取data block的位置
这样的设计其实也挺麻烦的,要一级一级地往下读,因此这种设计并没有被广泛采用,直到LFS提出20年后,闪存技术高速发展,F2FS被提出,LFS才被慢慢广泛使用。
F2FS
简介
F2FS是历史上第一个真正被广泛使用的日志文件系统。
如下图所示:F2FS的主体分为metadata和data两个区域,前者主要存储元数据,采用普通的随机读写方式。后者是存储文件数据以及inode的数据区域,是典型的追加写的模式(或者说叫序列写)。

元数据区域
元数据区域分为如下几个部分:
- 超级块(Super Block)包含一些基本的分区信息以及其他一些不变的信息,不是我们关注的重点
- 段信息表(Segemnt Info Tale,SIT) 包含数据区域内每个段的有效块的数量以及标记每个块是否有效的位图,该部分的元数据主要用于垃圾回收过程中需要搬移的段以及识别段中的有效数据
- 索引节点表(Node Address Table, NAT) 用于定位数据区域中的索引节点块,包括每个inode节点的地址等信息。
- 段摘要区域(Segment Summary Table,SST)数据区域中所有数据块的父节点信息,也就是一个反向索引(用于当当前节点的位置发生变化时候更新父节点信息)
- 检查点(CP): 保存文件系统的状态,方便崩溃和掉电后的系统崩溃等。
数据区域
和F2LS的结构基本相同,F2FS中的数据区域也由多个Segment排列而成。每个Segment中有多个数据块以及多个Inode节点,Inode用于索引数据块,而Inode的地址则被存储在元数据区中的NAT表中。由于NAT表的存在,F2FS中就不存在Inode map这种东西了。
Workflow
下面介绍下F2FS的工作流程。
写.和最开始的LFS一样,F2FS也是直接往段的尾部追加文件块和Inode信息,在写完文件块后LSFS会更新NAT表以把新增加Inode纳入NAT的索引中,这时候不要忘记旧Block已经无效了,因此这里还要更新SIT表更新有效性索引信息便于垃圾回收,请注意删除也是写的一种,因此这里不再独立讲删除流程.
读.为了读一个文件,F2FS会在NAT表中查询该文件所有的Inode节点的位置,并根据这些位置信息读取所有的Inode节点,最后根据Inode节点读取所有有效的文件Block,最后选最新(即有效)的Block组合到一起即可
垃圾回收.当如下两个条件发生一个时,F2FS会以一定的策略进行垃圾回收:
- 在追加文件块的时候发现整个文件系统中已经没有空闲段
- 文件系统的IO空闲的时候(有后台线程管理这个事情)
在上述两个条件满足一个的时候,文件系统会读取SIT表,也就是所有段内数据块的有效性信息,找到一些包含最少有效块的segment,并使用随机读写的方式删除所有的无效块,然后把所有的有效块挪到段的头部方便后面再次写入.这时候由于有大量的文件块被移动了,为了防止父节点找不到该数据块的情况,因此这里还需要修改SST表已更新父节点的信息.
F2FS的实际设计远比我这里写的要复杂,总之这篇文章的主要目的还是做个简单的总结.